
Why you want to use prefixed Node.js import for built-in modules
You might have seen imports like node:fs instead of a bare specifier like `fs`. We're here to talk about the difference between these 2 types of imports

Interesting links that I found this week:
TLDR:
Use
nodeprefix (likeimport fs from 'node:fs'orrequire('node:fs')) to import all built-in modules. Especially when dealing with apps using CommonJS modules, since it is possible to modifyrequire.cache. The prefix makes your intentions more clear, guarantees you're loading the built-in module. Some newly introduced modules likesqliteortestmake this prefix mandatory.
node:fs vs. fs: The Key Differences
While both aim to access Node.js's file system module, the way you import it matters. Let's look at the two common styles:
Using the bare specifier:

Using the node: prefix:

Now, let's break down the key differences in their behavior.
Code Clarity
When using a bare import specifier, you rely on the other devs' knowledge about built-in Node.js modules and assume they are familiar with all of them.
On the contrary, the node: prefix provides clarity by explicitly identifying the module as a core Node.js module.
It is a subtle difference, but an important one to reduce cognitive load and make your intentions clearer.
You can see it for yourself. Here is a file that contains multiple imports. Can you identify which ones are actually built-in modules?

You can find the answer in a new file where all built-in Node.js modules are prefixed with node:.
Interaction with require.cache
Node.js caches modules after their first load using require.cache to improve performance. However, it only works for modules that don't have the node: prefix. Those are loaded before checking the cache.
You can read the full source code in the CJS load file.
Here is the part with the prioritization of module loading. You don't need to read through the whole example and try to understand it. Just skim through the comments first, second, and third to see the order of loading and some explanations of what's going on there.
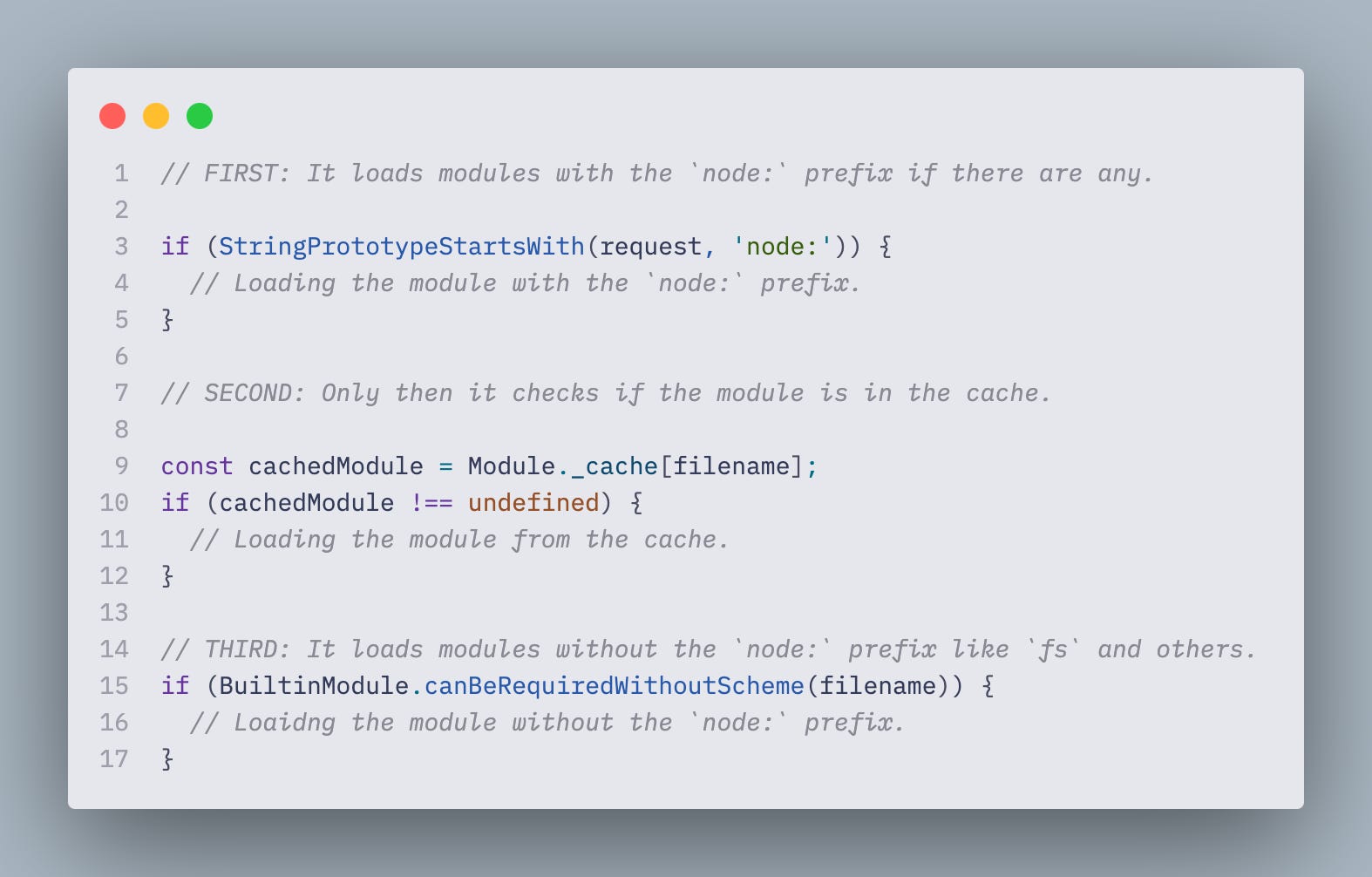
You can find the following description in the official Node.js documentation, which supports this claim:
Built-in modules can be identified using the
node:prefix, in which case it bypasses therequirecache. For instance,require('node:http')will always return the built in HTTP module, even if there isrequire.cacheentry by that name.
And
Some built-in modules are always preferentially loaded if their identifier is passed to
require(). For instance,require('http')will always return the built-in HTTP module, even if there is a file by that name.
What does it mean for us? It means that the cache, as a public API, can be directly accessed and modified by the code that runs in your Node.js app.
Here is a very simple and minimalistic example:

First console.log prints the content of fakeFs module that we've created. Simply because it was already presented in the cache. However, the second console.log, where we use the node: prefix, prints the content of built-in `fs` module.
This works because require.cache is a plain JavaScript object that can be modified at runtime. Subsequent require('fs') calls check this cache and, if an entry exists (even a manipulated one), will use it.
While require('fs') and require('node:fs') should generally return the same singleton instance after the first load, the node: prefix provides a stronger safeguard for the lookup mechanism itself against a "poisoned" cache entry for the _non-prefixed name_. This makes node:-prefixed imports inherently safer against such specific cache poisoning scenarios.
Is it still worth using the prefix when dealing with ESM?
Both CJS and ESM loaders in Node.js have a module cache. The difference is that the ESM cache is not publicly available for modifications, unlike the CJS cache.
Meaning that a potential security issue is mitigated by the loader design.
While cache modifications are not an issue, it would still be worth it to use node: prefix to make your intentions more clear. It doesn't cost much, if anything, especially in the era of AI and great tooling.
Wrap up
To solidify your understanding of the topic, I created a repository with 2 exercies. Brace yourself and try to complete them. Good luck!
The difference between using prefixed imports for Node.js built-in modules and bare specifiers heavily depends on the module system you're working with.
It is crucial to understand the difference when you're project is running with CommonJS, especially the part about require.cache potential modifications.
Despite the module system, prefixed imports make your intentions clearer and easier to understand for other developers. Therefore, I'd recommend sticking with it whenever possible.
Great post! Thanks for sharing